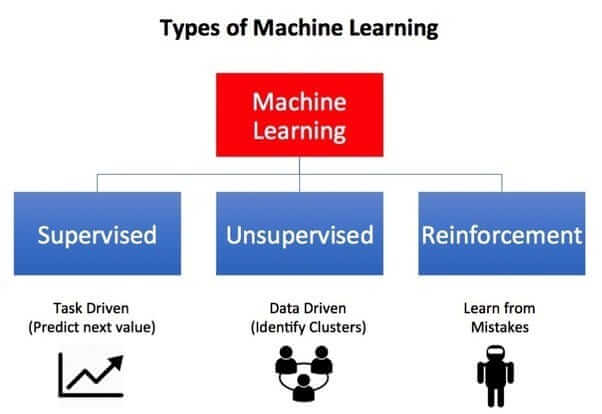
1. Supervised Learning
This is the most common type. The algorithm is trained on a labeled dataset. “Labeled” means that each training example is paired with the correct output answer (like a teacher providing the answers).
- Concept: Learn a mapping function from inputs (X) to outputs (Y).
Y = f(X) - Goal: Predict the correct label for new, unseen data.
- Analogy: A student learning with a textbook that has the answers in the back.
Common Algorithms: Linear Regression, Logistic Regression, Support Vector Machines (SVM), Decision Trees, Random Forests, and most Neural Networks.
It is further divided into two main categories:
A) Regression
- Goal: Predict a continuous numerical value.
- Example:
- Problem: Predicting the price of a house.
- Input Features: Size (sq. ft.), number of bedrooms, location, age.
- Output (Label): Price (e.g., $450,000, $525,100).
B) Classification
- Goal: Predict a discrete categorical label.
- Example:
- Problem: Classifying an email as “Spam” or “Not Spam”.
- Input Features: Words in the email, sender’s address, subject line.
- Output (Label): Category (“Spam” or “Not Spam”).
2. Unsupervised Learning
The algorithm is given data without any labels. Its goal is to find hidden patterns or intrinsic structures within the input data on its own.
- Concept: Find the underlying structure of the data.
- Goal: Discover groupings, associations, or reduce complexity.
- Analogy: A student is given a mixed bag of different fruits and asked to sort them into groups without being told what the fruit names are.
Common Algorithms: K-Means Clustering, Hierarchical Clustering, Principal Component Analysis (PCA), Apriori Algorithm.
It is also divided into key categories:
A) Clustering
- Goal: Group similar data points together.
- Example:
- Problem: Customer segmentation for a marketing campaign.
- Input Data: Customer purchase history, age, location.
- Output: Groups of customers with similar behaviors (e.g., “budget shoppers,” “luxury buyers,” “frequent weekend shoppers”).
B) Association
- Goal: Discover rules that describe large portions of your data (e.g., “if A and B are purchased, then C is also often purchased”).
- Example:
- Problem: Market basket analysis in a supermarket.
- Output Rule:
{Peanut Butter, Jelly} -> {Bread}(People who buy peanut butter and jelly are very likely to also buy bread).
C) Dimensionality Reduction
- Goal: Reduce the number of input variables (features) in a dataset while preserving the important information. This simplifies the model and visualizes high-dimensional data.
- Example: Compressing a high-resolution image into a lower-dimensional representation without losing its essential features.
3. Reinforcement Learning (RL)
The algorithm (called an agent) learns by interacting with a dynamic environment. It performs actions and receives feedback in the form of rewards or penalties.
- Concept: Learn through trial and error to achieve a long-term goal.
- Goal: Find the optimal actions to take in a given situation to maximize cumulative reward.
- Analogy: Training a dog. The dog (agent) tries different actions (sitting, rolling over). You give it a treat (reward) for correct behavior and nothing (or a gentle correction) for incorrect behavior.
Common Algorithms: Q-Learning, Deep Q-Networks (DQN), Policy Gradients.
Example:
- Problem: Teaching a computer to play a game like Chess or Go.
- Agent: The AI player.
- Environment: The chessboard.
- Action: Moving a piece.
- Reward: +1 for winning, -1 for losing, 0 for a draw. The agent learns which sequences of moves lead to victory.
Other Important Types (Hybrids & Specializations)
4. Semi-Supervised Learning
A blend of supervised and unsupervised learning. The model is trained on a dataset that contains both labeled and unlabeled data. This is very common in real-world scenarios where getting labeled data is expensive or time-consuming, but unlabeled data is plentiful.
- Example: Identifying objects in photos. You might have 100,000 unlabeled images and only 1,000 that are carefully labeled (e.g., “cat,” “dog,” “car”). The model uses the labeled data to learn the basics and the unlabeled data to refine its understanding of the data’s structure.
5. Self-Supervised Learning
A type of unsupervised learning where the data itself generates the labels. The system creates its own supervisory signal from the structure of the data.
- Example: Training a model to predict the next word in a sentence (like GPT models). The “label” is the actual next word in the text, so no human labeling is required.
6. Deep Learning
Not a separate category by learning type, but a powerful subset of machine learning that uses artificial neural networks with many layers (“deep” networks). Deep Learning can be used for Supervised, Unsupervised, and Reinforcement Learning tasks.
- Examples:
- Supervised: Image Recognition (Convolutional Neural Networks).
- Unsupervised: Generating new images (Generative Adversarial Networks – GANs).
- Reinforcement: Mastering complex games like StarCraft II (DeepMind’s AlphaStar).
Summary Table
| Type | Data Used | Goal | Analogy | Real-World Example |
|---|---|---|---|---|
| Supervised | Labeled Data | Predict an output | Learning with an answer key | Spam Detection, House Price Prediction |
| Unsupervised | Unlabeled Data | Find hidden patterns | Sorting items into groups | Customer Segmentation, Gene Sequencing |
| Reinforcement | Interaction & Rewards | Maximize long-term reward | Training a pet with treats | Self-Driving Cars, Game-Playing AI |
| Semi-Supervised | Mixed (Labeled & Unlabeled) | Improve learning with less labeled data | A tutor who checks some homework | Speech Analysis, Web Content Classification |
| Self-Supervised | Unlabeled (creates its own labels) | Learn representations from data itself | A student filling in blanks in a text | Large Language Models (LLMs like GPT) |